|
Если стоит задача сохранить музыку без потери качества,
при этом всё таки уменьшив её размер, уверенный выход
на сегодняшний день один - сжать её в mp3 с потоком
256 kbit/s и более. Много копий сломано по поводу
того, что за качество получается в результате и какой
кодек для этого лучше использовать - оригинальный
ISO или от института Fraunhofer. Есть, однако, некоторые
аспекты, которые раньше не поднимались, да и сейчас
их обсуждение можно редко где встретить...
Каюсь, я раньше любил ISO. Вообще, не знаю как сейчас,
а в 98-99 годах настрой был вполне определенный: ISO
- для 256, Fraunhofer - для того, что ниже. Но теперь
я изменил своё мнение. В этом виновато отчасти то,
что с заменой некоторой звуковой аппаратуры я получил
возможность слышать то, что раньше не слышал. Проводились
какие-то тесты, слушали, и так совпало, что всё, на
чем я лично пытался убедиться, маскировалио недостатки
ISO. Время изменилось, аппаратура тоже... И главное
- появился кодек .mp3 Producer V2 (Opticom), который
всё таки неплохо сохраняет частоты выше 16 кГц. Поэтому
теперь я для разнообразия объясню, почему на 256 надо
использовать именно Fraunhofer.
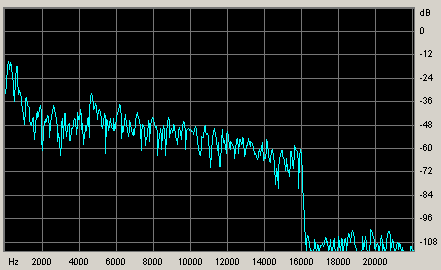
Раньше всё упиралось в довольно примитивный вопрос:
нужно ли сохранять частоты выше 16 кГц или нет. ISO
сохранял их, Fraunhofer, даже самый последний - якобы
нет. На самом деле это уже заблуждение. Мы брали усредненный
график распределения мощностей по частотам, смотрели
на ступеньку на 16 кГц, радовались и решали, что так
есть всегда:
 (после Fraunhofer. Исходно была ровная АЧХ после
16 кГц)
(после Fraunhofer. Исходно была ровная АЧХ после
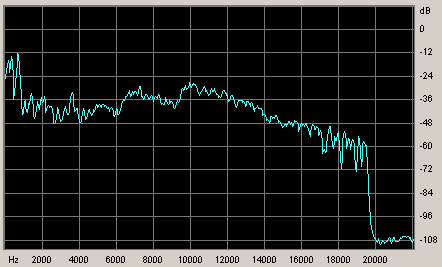
16 кГц) Реальная, а не усредненная картина выглядит намного
интереснее. В файле присутствуют моменты где этих
частот нет вообще, и моменты, где они сохранены в
полном объеме:
Что в усреднении дает как раз якобы спад. А на самом
деле это не пренебрежение к этим частотам, это просто
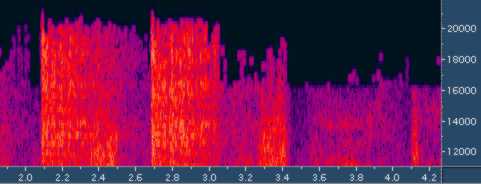
работа их психо-акустической модели. Лучше всего это
дело смотреть вообще сонограммой (почему раньше никто
не догадался?). По горизонтали - время, по вертикали
- частоты:
Довольно хорошо видно, что частоты выше 16 кГц еще
как сохраняются. Сильные высокочастотные звуки вполне
продолжаются без каких-либо спадов до 20 кГц. А то,
что иногда они не сохраняются - это и к лучшему, остается
больше потока для кодирования более важных частот.
Небольшое отступление.. Частоты выше 16
кГц в общем то нужны. Это факт. Но я никак не пойму,
для чего они нужны. С одной стороны, делаем синусоиду
-6 дБ частоты 16 кГц, слушаем. Одно условие - тут
нужна всё таки аппаратура хотя бы >$400, чтобы
она физически могла работать с такими частотами. Слышим!
Не то чтобы это звук, но ощущаем отчетливо. Но стоит
вспомнить, что мощность по частотам в реальных звуках
уменьшается с увеличением частоты. И вообще, ставим
более логичный эксперимент. Берем реальную музыку
с хорошим содержанием высоких, вырезаем под ноль всё
меньше 16 кГц, используя FFT фильтр. Это честная процедура,
в плане частот она делает именно то, что нам нужно,
без всяких переходных процессов на границе и т.д.
Слушаем. И лично я ничего не слышу. На разумной громкости...
Если поднимать громкость выше всяких разумных пределов,
лично на меня эффект только один - если это дело на
сильной громкости послушать хотя бы 40 секунд, 30
минут головной боли обеспечено. Они однозначно воспринимаются,
хотя бы в качестве раздражителя, а не звука, и следовательно
- желательно их сохранять. Для полноты картины, так
сказать. :)
В общем, вывод: не знаю, как товарищи
из Fraunhofer составляли свою акустическую модель,
не иначе как доводя своих сотрудников - подопытных
до крутой мигрени, но что-то такое они составили и
для частот выше 16 кГц. На этом вопрос лично для меня
закрылся.
А теперь собственно о том, в чем ISO гораздо хуже
Fraunhofer-а. Сжатие в Layer3 происходит по блокам.
Примитивно говоря: для каждого блока происходит сначала
разложение сигнала на составляющие частоты, затем
применяется акустическая модель, выбрасывая ненужные
компоненты отдельных блоков, а при воспроизведении
все частоты снова складываются. Однако тут встает
вечная проблема частотного анализа: чем больше разрешение
по частоте, тем меньше разрешение во времени. Поэтому
в Layer3 есть два типа блоков - обычный и уменьшенный.
Обычное сжатие идет обычными блоками довольно большого
размера, за счет чего с одной стороны достигается
хорошее частотное разрешение и соответственно хорошее
сжатие. Мы выбрасываем значительную часть информации
о расположении частот во времени. Но когда в источнике
наблюдается какой-то эффект, например удар тарелок,
который было бы нежелательно размазывать во времени,
кодер переходит на короткие блоки и кодирует этот
момент более тщательно. Локальное сжатие при этом
сильно падает, но закодировать резкий звук резко -
гораздо важнее.
И это первая вещь, которая к чертям сломана в ISO
кодеке. Вернее сказать, недоделана. Он почти не переключается
на маленькие блоки тогда, когда это нужно, и часто
делает это там, где не нужно. Иллюстрация - берем
резкий звук и смотрим, что с ним приключается:
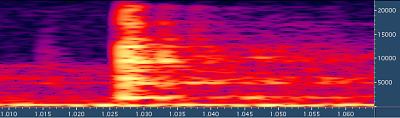 Исходный звук
Исходный звук
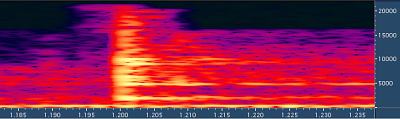 После Fraunhofer
После Fraunhofer
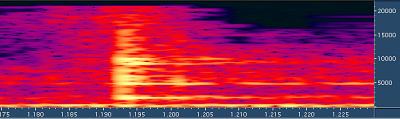 После ISO
После ISO ISO кодек сильно размазал удар во времени. Он просто
не переключился на короткий блок, хотя следовало бы.
Появляются довольно интересные искажения, с которыми
нам теперь предстоит бороться, в связи с переходом
на цифровые алгоритмы сжатия - например, пре-эхо.
Отзвук начинается раньше самого звука.
 Исходный звук
Исходный звук
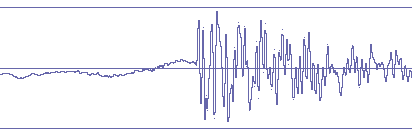 После Fraunhofer
После Fraunhofer
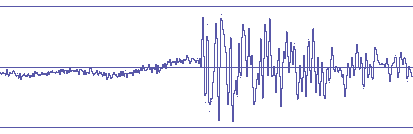 После ISO
После ISO На самом деле это всё не так страшно, как может показаться
по картинкам. Даже в самом плохом варианте это всё
не настолько плохо чтобы было слышно отчетливо. В
музыке это расслышать трудно. Но общая картина звука,
тем не менее, иногда становится менее четкой в ISO
кодеке. Есть конечно примеры, которые показывают разницу
сразу. Например - хорошо записанные звуки кастаньет.
Вот два файла по 210 кб, десяток секунд, закодированные
ISO (256_castanets_iso.mp3,
210Кб) и Fraunhofer (256_castanets_iis.mp3,
211 Кб). Разницу очень хорошо слышно в наушниках,
но и без них тоже вполне можно различить.
Тут я немножко продублировал сайт "LAME Ain't an MP3 Encoder". Товарищи
занимаются доводом ISO кода до ума. В том числе, пытаются
починить переключение на мелкие блоки, пре-эхо, да
и вообще всё то, что плохо работало или было недоделано
в оригинальном варианте. На самом деле в ISO коде
очень много ошибок и недоделок. Что, впрочем, не мешает
ему работать достаточно хорошо на больших битрейтах,
они же хотят доделать его так, чтобы он смог нормально
закодировать в 128 кбит/с.. В принципе, то, что у
них получилось, уже вполне способно конкурировать
и с Fraunhofer, но пока Fraunhofer всё же лучше, причем
на любых потоках.
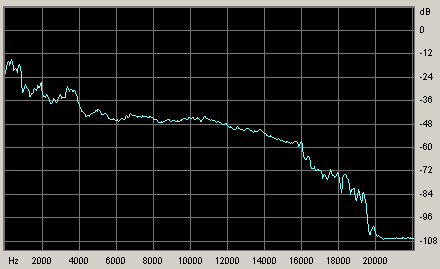
Хотелось бы развеять еще один миф, о том, что Layer3
- 256 оставляет почти строго оригинальный звук. Нет,
это настолько далеко не так, что можно удивится, впервые
ощутив разницу. У нас почему-то принято измерять качество
форматов сжатия, строя графики усредненной частотной
передачи. Это позволяет конечно судить, не отрезал
ли кодек чего лишнего, но не более, ведь сама суть
всех современных алгоритмов сжатия звука дает отличные
усредненные частотные параметры, так что как гарантия
качества эти замеры совершенно бесполезны. Всё нужно
смотреть в динамике. Оценивать временные параметры,
а не частотные. Мы гораздо менее к ним чувствительны,
и на этом тоже основано сжатие. Вот иллюстрация, опять
же сонограмма:
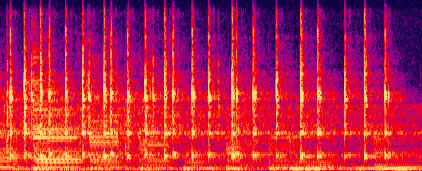 Исходный звук
Исходный звук
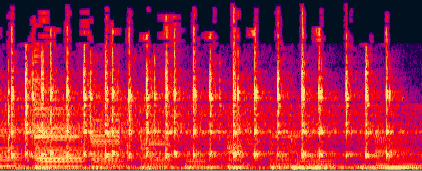 После Fraunhofer
После Fraunhofer
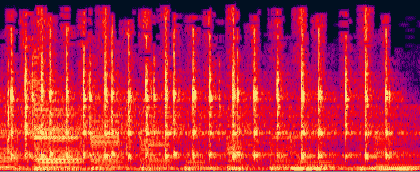 После ISO
После ISO Разницу можно видеть даже не особо утруждаясь. Даже
профессиональный кодек от Fraunhofer настолько размазал
частоты по времени по сравнению с оригинальным звуком,
что точной копией оригинала это может считаться с
большой натяжкой. А уж частоты выше 16 кГц у обоих
кодеков закодированы настолько непохоже на оригинал...
Искажения любого частотно-акустического кодирования
будут преследовать и MPEG Layer3 на высоких потоках.
В данный момент есть всего два фактора, которые стоит
принимать в расчет при кодировании с потоками 256
или 320 кбит/с:
- Трудности с передачей резких звуков. Сигнал получается
слегка размазанным во времени в пределах блока частотного
разложения. Сейчас (в mp3) для этого существуют
короткие блоки, на которые, при необходимости, переключается
кодировщик. Это, однако, лишь уменьшение значимости
проблемы, а не её полное устранение. На сонограммах
выше видно, что в любом случае присутствует размытость
всех резких явлений во времени - хоть размытость
в пределах короткого блока - лучше, чем в пределах
длинного, обычного, позволяющего добиться лучшего
сжатия.
- Слабая, не совсем точная передача моментов, перегруженных
мощными звуками. На данный момент алгоритм коррекции
такой: в потоке данных mp3 имеется буфер, который
позволяет экономить некоторую часть потока, чтобы
в нужный момент воспользоваться накопленным резервом
и затратить гораздо больше данных на кодирование
узкого участка. К сожалению, буфер этот невелик,
а дальнейшее развитие этой идеи - переменный поток
- VBR - пока не имеет разумной и качественной реализации.
На больших потоках, однако, способность Layer3 передавать
перегруженные моменты далеко превосходит нашу собственную
способность их слышать и способность аппаратуры
их воспроизводить, так что ничего страшного и здесь
нет.
Любой из представленных алгоритмов кодирования, да
и любой из тех, которые будут созданы позднее, будут
так или иначе вносить искажения даже на больших потоках
- более 256 кбит/с. И очень важно отличать объективные
критерии оценки искажений от субъективных. Распространенные
в конструировании звуковой аппаратуры тесты синтетическими
сигналами - отдельными импульсами, к примеру - почти
не дадут никаких результатов, по которым можно было
бы судить о качестве кодирования реальных звуков.
Человек слишком непривередливое существо, чтобы чувствовать
все эти нюансы на слух. Проводились профессиональные
тесты на прослушивание сжатых материалов, и волноваться
всё же не стоит - Layer3 на 256 не теряет ни временных,
ни частотных параметров хоть сколь заметным человеку
образом. Мы никогда не услышим этой разницы, как не
услышали её профессиональные слушатели, задействованные
в тестах ISO (международной организации по стандартизации,
в том числе оговаривающей формат MPEG1 Layer3), хотя
можем ясно видеть её на экране. Но одну вещь надо
обязательно учитывать: если вы хотите оставить за
собой возможность обрабатывать каким-либо образом
звук, его нельзя сжимать в Layer3. Например, даже
довольно малое изменение тональной окраски звука приведет
к тому, что все частотные изъяны вылезут и тут же
слышны как звон/бульканье, неравномерность звука,
а любая реверберация или эффекты задержек наряду с
предполагаемым эффектом дадут еще целую кучу дополнительных,
неожиданных артефактов.
Назад
|